A Visual Explanation of Self Attention
Prerequisite
Please read this post before moving ahead: attention in simple terms
Background
In this blog, we reviewed attention in the context of encoder-decoder network where given the current decoder hidden state (query), the attention model “probes” over all of the encoder hidden states (values), to calculate attention/context vector for the current decoding step.
In this blog, we are going to review another type of attention mechanism, where attention vector is obtained from the query and the values of the same layer, known as self-attention. For a given hidden state, the attention vector in this case “attends to” all the hidden states from the same layer.
Let me illustrate.
Graphical Representation
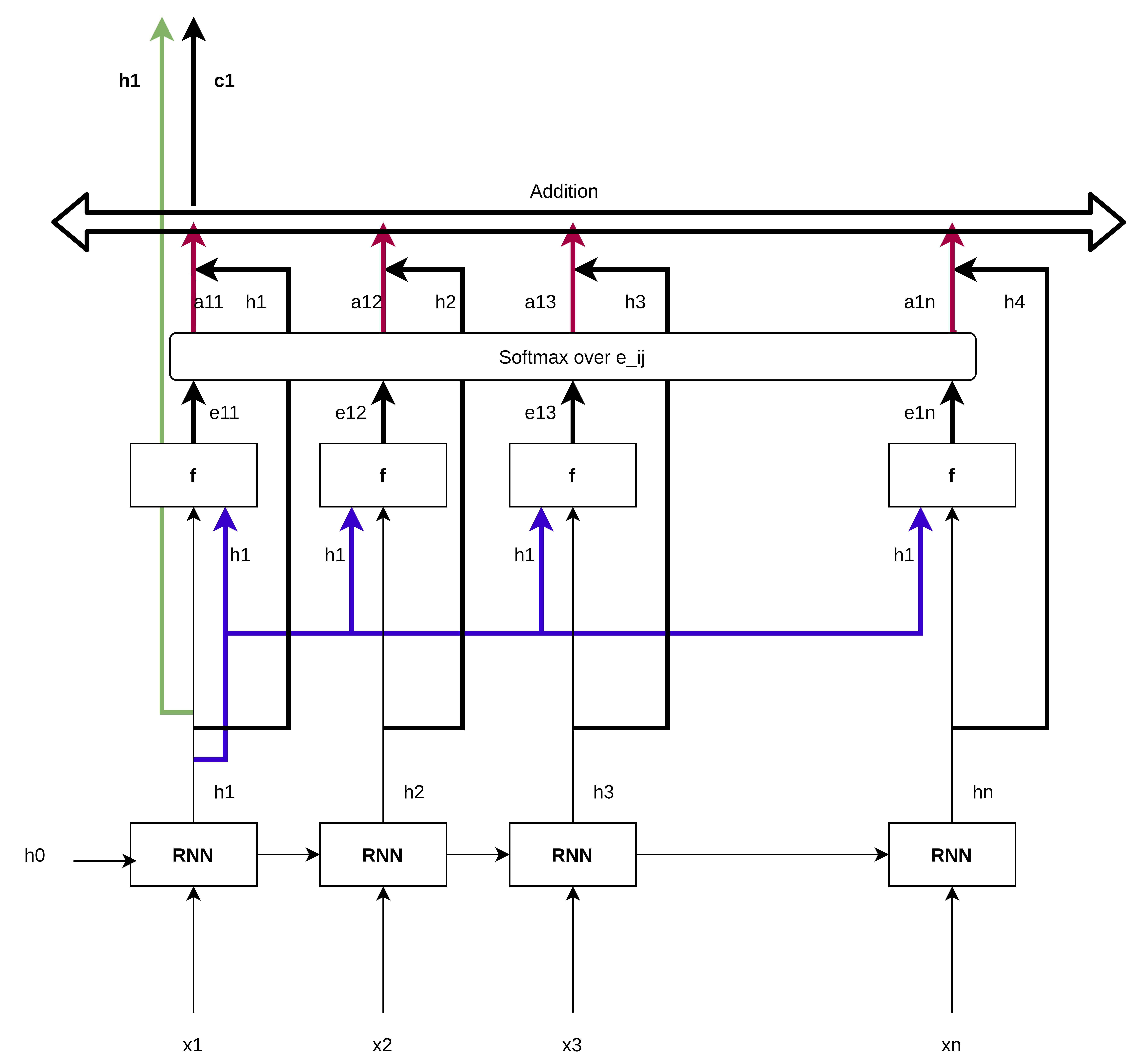 Figure 1: Self-attention mechanism to calculate context vector for the first sequence element.
Figure 1: Self-attention mechanism to calculate context vector for the first sequence element.
Explanation
Let’s take a closer look at the image above and try to understand what is going on.
- We have a sequence of inputs $X = (x_1, x_2, x_3, …, x_n)$.
- Specifically here, we are using an RNN to model the sequence $X$. This argument/approach is general though.
- The initial hidden state of the RNN is $h_0$ and for $X$, the RNN outputs $H$, a sequence of hidden states $(h_1, h_2, h_3, …, h_n)$ corresponding to each element of $X$.
-
Let’s calculate the attention/context vector $c_1$ for the first timestep. The same process can be applied to calculate the rest of the attention/context vectors. The process followed here is described in this blog. Please make sure you have understood it. It’s THE prerequisite for this blog.
-
The hidden state $h_1$ is shared across all timesteps of the sequence as can be seen in the blue colored arrows.
-
For each timestep, we now have two vectors: the hidden state of that timestep and this shared hidden state.
-
With these two vectors as inputs to the function $f$, we get a score $e$. This can be seen in the rectangle which has the function $f$ inside it with two inputs: $h_1$ and the hidden state at that timestep.
-
To illustrate further, we get the score $e_{11}$ as a function of the shared hidden state (which is $h_1$) and the hidden state $h_1$ : $f(h_1, h_1)$. Similarly, $e_{12} = f(h_1, h_2)$, $e_{13} = f(h_1, h_3)$, …, $e_{1n} = f(h_1, h_n)$.
-
Once we have $e_{11}, e_{12}, e_{13}, …, e_{1n}$, we take softmax over them to get $a_{11}, a_{12}, a_{13}, …, a_{1n}$.
-
with $a_{1j}$ as weight for $h_j$, we take the expectation of all the hiddens states to obtain the context vector: \begin{equation} c_1 = \sum_{j=1}^{n} a_{1j}h_j \end{equation}
-
- Similarly, we can obtain $c_2, c_3, …, c_n$ by repeating above Step(4) where the shared hidden state would be $h_2, h_3, …, h_n$ resp. This gives us a sequence of context vectors $C = (c_1, c_2, c_3, …, c_n)$.
- The generic formula to get the context vector for the $i^{th}$ timestep is: \begin{equation} c_i = \sum_{j=1}^{n} a_{ij}h_j \end{equation}
- For each hidden state $h_i$ given by the RNN, we now have an attention/context vector $c_i$ given by the attention model. We concatenate the hidden state and the context vector at each timestep and feed that as input to the next layer: $X^{next} = conc(H, C) = ([h_1, c_1], [h_2, c_2], [h_3, c_3], …, [h_n, c_n])$.
Conclusion
Steps (1) through (7) show us how to calculate self attention vectors for a given sequence. Along with the RNN hidden states, we use these context vectors to provide some extra information to the next layer.
Here, RNN as a sequence model is not really necessary. We could use a CNN or just a fully connected layer instead of an RNN. The outputs of this layer for each sequence element will be used to calculate the context vectors. Let $L$ be either a 1D-CNN or an FC layer or any layer which takes in $x$ and gives another vector.
- Input: $X = (x_1, x_2, x_3, …, x_n)$
- $H = (h_1, h_2, h_3, …, h_n) = L(X) = (L(x_1), L(x_2), L(x_3), …, L(x_n))$
- $C = (c_1, c_2, c_3, …, c_n)$ where $c_i = \sum_{j=1}^{n} a_{ij}h_j$
————————————- END ————————————-